
(If you would like to read the previous T-SQL Tuesday Retrospective entries, visit this link.)
In October 2010, Sankar Reddy asked us which misconceptions we’ve been labouring under when it comes to SQL Server:
The possibilities for writing up a post on this topic invloving SQL Server are enormous even if you are a novice blogger or the industry expert on SQL Server. So get ready with your [misconceptions, myth-busters, de-mystifiers, do you know, back to basics, fact checking] posts on SQL Server and help the community learn more stuff while setting the facts straight.
One misconception I’d like to talk about is which data types are supported by columnstore indexes. To remind you, a columnstore index stores data by column instead of by row, which allows for dramatic storage compression as well as up to 10x query performance when performing analytics-style queries. Furthermore, with a clustered columnstore index (as opposed to a nonclustered columnstore index), the index is the data itself, just like a regular clustered (rowstore) index.
Recently I have been working with a customer that needs to store XML data online (i.e. available for querying) for a minimum period of ten years. They are running on SQL Server 2014, and have been using gzip compression at the application layer to store the XML data in a VARBINARY(MAX) field. If they were on SQL Server 2016 already, they might use COMPRESS and DECOMPRESS instead, but ultimately the data is persisted the same way.
Recently I learned that NVARCHAR(MAX) is a supported data type for a clustered columnstore index in SQL Server 2017 and later. Unfortunately, SQL Server Management Studio (SSMS) does not agree. If you try to create a clustered columnstore index on a table in a database that is on compatibility layer 140 or higher, SSMS will tell you it isn’t possible.
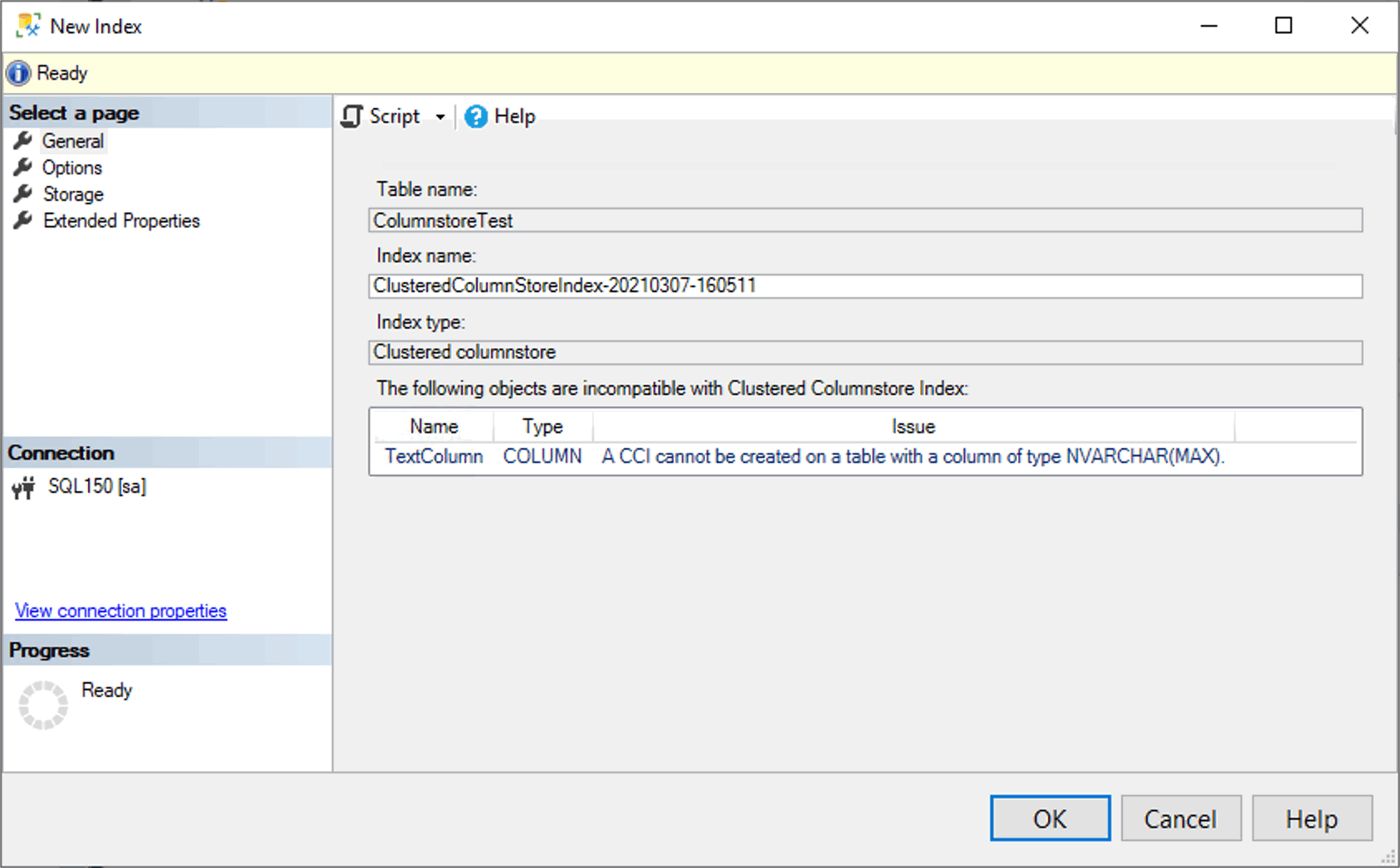
In fact, even when you script out the index creation using Transact-SQL (T-SQL), the SSMS parser still underlines parts of the script to imply that it doesn’t work, giving a seemingly unrelated warning about included columns:

Running the query works just fine, and it creates the clustered columnstore index without any issues. In fact I was only able to discover that SSMS was wrong because I was reading the official documentation, specifically the section on data types (emphasis in red added):
Columns that use any of the following data types cannot be included in a columnstore index:
- ntext, text, and image
- nvarchar(max), varchar(max), and varbinary(max) (Applies to SQL Server 2016 (13.x) and prior versions, and nonclustered columnstore indexes)
- rowversion (and timestamp)
- sql_variant
- CLR types (hierarchyid and spatial types)
- xml
- uniqueidentifier (Applies to SQL Server 2012 (11.x))
Once I cleared up this misconception I was able to experiment with storing and querying XML data for my customer using NVARCHAR(MAX). I discovered that they will be able to store between three and four times the XML data they currently do, if I use a clustered columnstore index on that table.
Compared to the native XML data type, the compression in my testing was as high as 85%. When compared against gzip compression (i.e. COMPRESS and DECOMPRESS using VARBINARY(MAX)) the compression was still as much as 65%. An additional saving came from removing many of the supporting non-clustered indexes that were used for improving query performance. Despite the queries needing to do a full clustered columnstore index scan, the SELECT performance was just as fast as before. Even so, the tables in question still need a unique constraint for referential integrity, so I kept the primary key constraint on the underlying table, but made it a non-clustered index with PAGE compression to make it smaller.
Summary
While the customer does need to make some fairly radical schema changes to the database — which will require some downtime in order to convert and compress the necessary objects — the trade-off is definitely worthwhile. On the application side, no changes are required. Stored procedures will continue accepting compressed binary data (we don’t want to send around large uncompressed XML strings over the network), but will decompress and persist the data as NVARCHAR(MAX), which in turn is compressed by the columnstore index.
So, there you have it. Sometimes the tools we have come to trust can cause misconceptions. I am submitting a write-up to the SSMS team describing this bug so that it can be addressed in a future version.
Photo by Gabriel Manlake on Unsplash.
As of this writing, SSMS 18.9.1 has included fixes for the two bugs described.
Comments are closed.