
TL;DR: No.
A customer recently brought up an interesting thesis, that if you edit a table’s values using SQL Server Management Studio (SSMS) using the edit feature, that the table is dropped and recreated in the background when you commit the changes.
This is false, but there had to be a good reason why they were under this misapprehension.
Proving the case
In this screenshot, I have a simple table with three columns:
ID: int, primary key, auto-incrementingName: nvarchar(255), not nullCity: nvarchar(255), not null
When I right click on the table in SSMS Object Explorer and select Edit Top 200 Rows, I can modify the values as needed and even add or delete rows. When I am done with the edit, I click into a row above or below where the edit took place, and the change is committed. The table is not recreated.
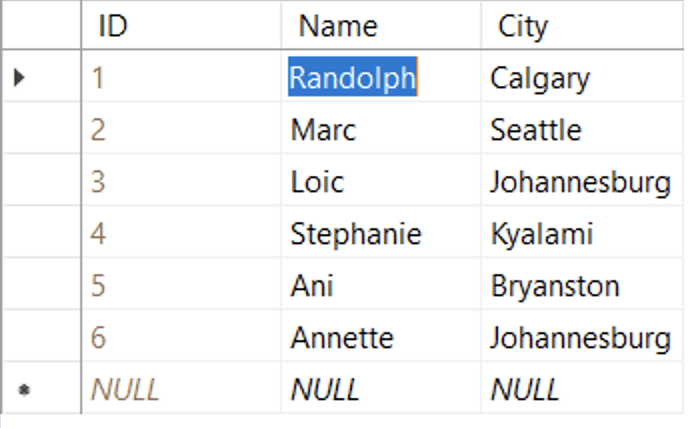
If you are playing along at home, you can create an XEvent Profiler session in SSMS. Here you’ll see just the row with “Randolph” being modified. Note that the entire row is being updated behind the scenes, but at least it’s not the entire table.

If you can’t read the text in the screenshot, it says:
exec sp_executesql N'UPDATE TOP (200) Test SET Name = @Name WHERE (ID = @PARAM1) AND (Name = @PARAM2) AND (City = @PARAM3)',N'@Name nvarchar(8),@PARAM1 int,@PARAM2 nvarchar(5),@PARAM3 nvarchar(7)',@Name=N'Randolph',@PARAM1=1,@PARAM2=N'Frank',@PARAM3=N'Calgary'
P.S. If you have replication enabled on a table and want to edit the table in SSMS, updates to the Replication GUID column are usually rolled back by a trigger. While you’re not specifically editing that replication column, it does participate in the generated UPDATE statement which could cause a rollback.
What led them to this conclusion?
After some back and forth I realised it was a misunderstanding based on a situation in SSMS which does cause a table to be dropped and recreated under certain circumstances, namely modifying the table structure.
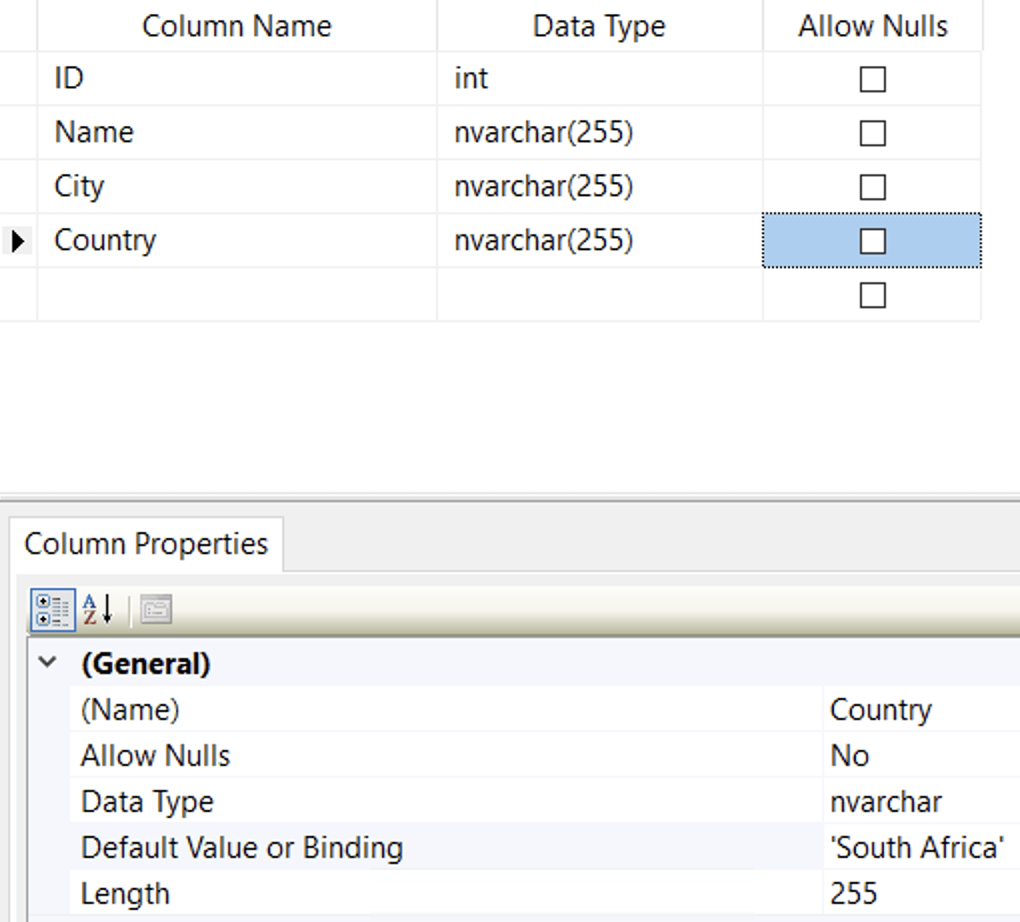
This isn’t always the case. For example, if I go into the table designer and add a new column to the end, the script that is generated will have an ALTER TABLE ADD ... statement, which is what we see in the next two screenshots.
On the left, I am adding a Country column with a default constraint, and on the right you can see a small section of the code that is generated:
ALTER TABLE dbo.Test ADD
Country nvarchar(255) NOT NULL CONSTRAINT DF_Test_Country ('South Africa')
GO
 |
 |
When does it actually cause a drop and reload?
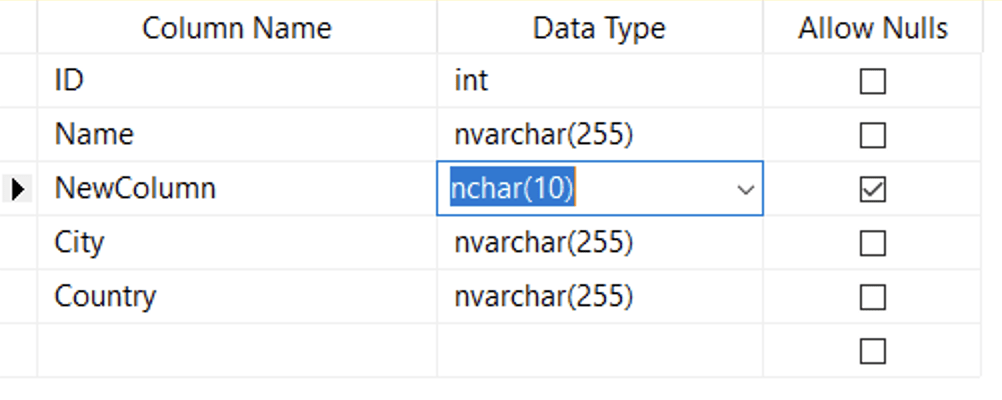
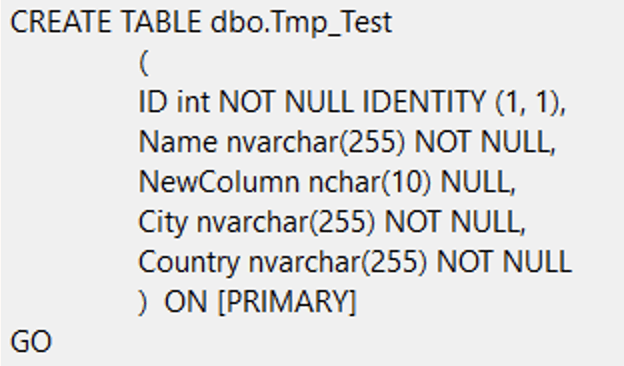
So when does dropping and recreating the table take place? It happens in scenarios like when you change the column order of the table, or insert a new column that isn’t at the end. In this next example, I am adding a column called NewColumn between Name and City on the left. On the right you see a sample of the script that is generated, which creates a new table called dbo.Tmp_Test, with the new schema. After this, there is an additional step (not shown) which:
- copies the data from the old table into the new one
- drops the old table
- renames the new one to the old name
- recreates any foreign key relationships and check constraints
 |
 |
Summary
Although updating rows is best done in a Transact-SQL script or through application code, there’s nothing inherently bad about editing rows in a table in SSMS, otherwise the feature wouldn’t exist. The main disadvantage is that it is very bad for performance, as it is populating the grid row by row, and there is no undo feature if you make a mistake.
Leave your thoughts in the comments below.