This post has nothing to do with SQL Server, but if you like performance tuning, stick around.
I learn technology by using it, pushing it to its limits, finding out how it breaks. I jokingly refer to myself as a living edge case because I will do something with your product that you might not have expected.
(If you’re looking for a beta tester, I’m definitely your man.)
By the same token, I write a lot of applications (in C#, my language of choice) to test theories and learn new things.
I have created a word puzzle game (no, you’ll never see it in the wild) that has as its list of permitted words a dictionary of approximately 300,000 English words. The list is a text file in ANSI format and smaller than 3MB.
The puzzle game works along the lines of the Scrabble® board game, with a set of random letters assigned to each player.
The trick for me was to limit the possible words from the main dictionary, based on the current player’s letters, to validate against. Unfortunately, even holding the full dictionary in memory in a List<string>() object was very (very) slow to filter. It was taking up to 7 seconds each time the letters changed.
I wrote to my friend, André van der Merwe, to ask him for help. My goal was to find all possible words with each letter combination, in the fastest possible way, ordered by longest to shortest. Performance is a feature.
André suggested I use a trie to hold my word list. This is principally how autocomplete algorithms work, where each letter in a word is the root of one or more words starting with that same sequence of letters. The computer reduces the list of possible words by following the path down the tree.
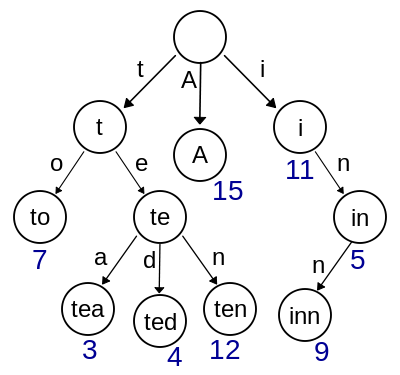
(I also call this a radix tree, but André correctly informed me that it’s not quite the same thing. Radix trees are more compact.)
A trie would make my search for words extremely fast because one of the properties of a trie is that each letter has a Boolean value (true or false) if it is the final letter of a word.
Unfortunately, every time I switched to a new player in the game, the entire word list had to be loaded into memory to be filtered against. For four players, this needed 250MB of RAM because a trie uses a class for every letter, and my word list was consuming over 60MB.
I work with data a lot. This is after all a SQL Server blog. I realised I didn’t need the entire dictionary in memory, ever. My players get up to 12 letters to work with, so I could eliminate words longer than that, which meant I could filter the word list before even knowing the player’s letters. What if I filtered the length and the player’s letters at the same time as building the possible word list?
Clearly this was a problem for lazy loading, a design pattern that says you should only load data into memory when you need it.
My solution was to read the word list off persisted storage (the hard drive) one word at a time, and if it had 12 letters or less, and could be made up using the letters in the player’s set, only then would it be loaded into that player’s trie.
Problem solved! Each player’s trie loads in under 30ms off SSD storage and 70ms if the word list is loading off a spinning hard drive. Even better, the memory footprint for each trie is only 12MB. This is still much larger than the 2.7MB of the List<string>() object, but a good trade-off with performance.
For reference, I eventually used this C# implementation, which André and I adapted.
What coding performance tricks have you used lately? Let me know on Twitter, at @bornsql.