
In 1983, Cyndi Lauper recorded the Billboard chart-topping single, Time After Time, which went on to win the hearts of many lovers in the three decades since then.
In 1985, Marty McFly used a DeLorean, invented by scientist Doc Emmett Brown, to travel back to 1955, where he met and interacted with his parents, Lorraine Baines and George McFly, before Lorraine and George fell in love.
In SQL Server 2016, we have a new feature, which I believe Microsoft has been working on for some time, called Temporal Tables.
I assure you that these are all related. In the words of Cyndi herself:
If you fall, I will catch you, I will be waiting
Time after time
Temporal tables allow us to retrieve the state of a table, at a specific point in time, using a method called effective dating. Not only useful for auditing and forensics, temporal tables can help if data is accidentally deleted, or perform trend analysis in a simpler way.
The next few posts will cover the broad strokes of this feature, explain how it works, and when to use it.
How Does It Work?
When we say that temporal tables are effective-dated, we need to jump into our DeLorean, and travel back to 1955 to look over the shoulder of Lorraine’s bank manager. When she opened her account in 1952, the [AccountName] column for her bank account would have said “Lorraine Baines”.
(I’m not getting into data models and a separate column for [FirstName] and [Surname] here — that’s a T-SQL Tuesday topic.)
Let’s assume this is the Accounts table:
-- IF EXISTS is a new SQL Server 2016 feature!
DROP TABLE IF EXISTS [dbo].[Account];
GO
CREATE TABLE [dbo].[Account] (
[AccountID] INT IDENTITY(1, 1) NOT NULL,
[AccountNumber] BIGINT NOT NULL,
[AccountName] NVARCHAR(255) NOT NULL,
[Address] NVARCHAR(1000) NOT NULL,
[Telephone] NVARCHAR(20) NOT NULL,
[CreateDate] DATETIME2(7) NOT NULL,
[ModifiedDate] DATETIME2(7) NOT NULL,
CONSTRAINT [PK_Account] PRIMARY KEY CLUSTERED ([AccountID] ASC)
);
GO
-- Default constraints for the Create and Modified Dates
ALTER TABLE [dbo].[Account] ADD CONSTRAINT [DF_Account_CreateDate]
DEFAULT(SYSUTCDATETIME()) FOR [CreateDate];
GO
ALTER TABLE [dbo].[Account] ADD CONSTRAINT [DF_Account_ModifiedDate]
DEFAULT(SYSUTCDATETIME()) FOR [ModifiedDate];
GO
This is how it looks in my SQL Server Management Studio, as we’d expect:
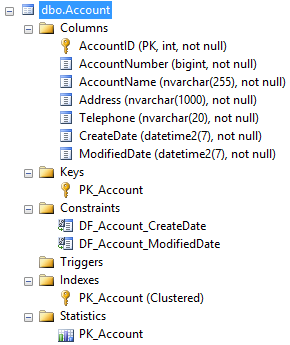
Now we insert our row:
INSERT INTO [dbo].[Account] (
[AccountNumber],
[AccountName],
[Address],
[Telephone]
)
VALUES (
5551112233,
N'Lorraine Baines',
N'1727 Bushnell Avenue, Hill Valley, CA, 90101',
N'310-555-1212'
);
GO
Later, when she got married to George, she took her husband’s last name and became “Lorraine McFly”. The database at the bank would have been updated with her new information, and that would be that. Whenever querying the accounts table, her bank manager would see her new name (or address, or telephone number).
UPDATE [dbo].[Account]
SET [AccountName] = N'Lorraine McFly',
[ModifiedDate] = SYSUTCDATETIME()
WHERE [AccountID] = 1;
GO
What if we made a mistake, and wanted to see what her old name was? What if we wanted to track down when her name changed, or what her old address was, or see how many people changed their addresses over a five year period?
I have designed a few auditing and logging systems in my career, and the general consensus is to record how the data used to look, and store it somewhere. This might be done with a series of stored procedures or triggers, on each table, using DELETED.* data.
That in turn might be stored in an archive table or database, a read-only filegroup, or an XML table somewhere, that we would have to query separately to the primary table, perhaps doing a complex JOIN to get current data as well.
Being a custom solution, it would add maintenance overhead, contain bugs, and have to be wrapped in transactions and / or slow TRY ... CATCH blocks, to be on the safe side. We might have an update and delete trigger for each table, which means three times the pain when doing any Data Definition Language (DDL) operations.
Now let us imagine that the bank used temporal tables. All data modification (DML) changes would be applied in the same manner. However, aside from marking the table as a temporal table, with the concomitant columns, there is no need for a custom solution. No need for triggers or stored procedures to track changes. No need to maintain an archive database. No need to query archived data restored from tape or microfiche.
In fact, it is as simple as using additional parameters on a SELECT statement: FOR SYSTEM_TIME AS OF, and FROM ... TO (for example). If we give that parameter a date and time, we can see how the data looked on Lorraine’s account, at an exact point in time.
How Do I Make A Temporal Table?
We can create a new table as a temporal table, or we can convert an existing table (with a few limitations).
Temporal tables require a clustered index. That said, I think every table in your database should have a clustered index anyway.
SQL Server 2016 Books Online shows us the dry syntax for creating new, or modifying an existing table, to make use of this effective dating, but let’s walk through it together here as well.
We need two new columns in our table. These should be DATETIME2(7), which adds an additional 16 bytes to our row length.
Keep this in mind for tables with a lot of churn, because we will generate a lot of data that has to be written to the history table, and 16 bytes adds up for millions or billions of changes.
Nevertheless, if you already implement an archival system, and keep track of when rows change (using a CreateDate and ModifiedDate column for instance), you’re already halfway there.
While we can choose the names of our effective dated columns, the documentation uses SysStartTime and SysEndTime, which I will also use in this post.
The SysStartTime will record when the row was created or modified (the effective date of the change). This is an important distinction from, say, a column that records just the CreateDate of a row. If we need to know the CreateDate of a row, we may be more comfortable leaving in our CreateDate column and adding the two new columns to that.
Of course, if we have a ModifiedDate-type column, that falls away entirely under this design. Win!
Once we’ve created our start and end time columns, we need to tell SQL Server to convert the table to a temporal table.
This is done in two stages. Firstly, we have to tell SQL Server that the two new columns will be the start and end of a temporal period.
-- Adds two new PERIOD columns and sets the temporal rules
ALTER TABLE [dbo].[Account] ADD PERIOD
FOR SYSTEM_TIME([SysStartTime], [SysEndTime]),
[SysStartTime] DATETIME2(7) GENERATED ALWAYS AS ROW START
HIDDEN NOT NULL
CONSTRAINT [DF_Account_SysStartTime]
DEFAULT SYSUTCDATETIME(),
[SysEndTime] DATETIME2(7) GENERATED ALWAYS AS ROW END
HIDDEN NOT NULL
CONSTRAINT [DF_Account_SysEndTime]
DEFAULT CONVERT(DATETIME2, '9999-12-31T23:59:59.9999999');
GO
Notice that SysEndTime is set to the largest possible value allowed for a DATETIME2 column. This is how SQL Server knows (and we know) that the row is current when viewing the data.
(The HIDDEN property is optional and will hide these columns from a standard SELECT statement for backward compatibility with our application and queries. You cannot apply the )HIDDEN property to an existing column.
Secondly, we must enable SYSTEM_VERSIONING, and define a history table to store the historic values. While we can create a history table ourselves (and if we have storage considerations, this might be a good idea so that the data is stored in a different file group), we only need to define a table name. If it doesn’t exist, SQL Server will create it for us. If it does exist, and has the same structure (column names can be different), it will use that table.
-- Make sure the History schema exists
ALTER TABLE [dbo].[Account]
SET (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [History].[Account],
DATA_CONSISTENCY_CHECK = ON
)
);
GO
As Books Online states, it is “highly recommended to set SYSTEM_VERSIONING with DATA_CONSISTENCY_CHECK = ON to enforce temporal consistency checks on existing data.”
As soon as we run the second ALTER TABLE command, and the history table is created or checked, we will now have a temporal table. It’s a metadata operation.
This is how it looks in my SQL Server Management Studio. Notice that the History table was created automatically, based on the structure of the primary table:
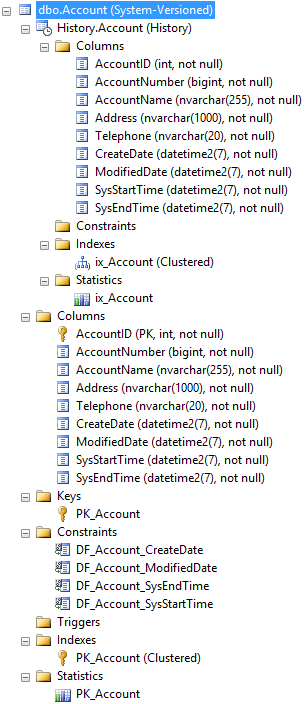
Now all changes are recorded by the database, in a history table, which is directly linked to the primary table, without needing any triggers or stored procedures.
It is not possible to externally modify the history table while it is linked to the primary table. Any change to the primary table is recorded in the history table by recording what the row looked like before the change.
And querying is a breeze. The main benefit for my use is to see what data looked like at a specific point in time, but we can also see what the table did between a start and end time, how the rows changed, and so on. There are performance considerations for each.
Let’s change Lorraine back to Baines and see how it looks:
UPDATE [dbo].[Account]
SET [AccountName] = N'Lorraine Baines',
[ModifiedDate] = SYSUTCDATETIME()
WHERE [AccountID] = 1;
GO
-- SysStartTime and SysEndTime explicitly named, or they will
-- not show up in the results, as they are hidden columns
SELECT [AccountID],
[AccountName],
[AccountNumber],
[Address],
[Telephone],
[CreateDate],
[ModifiedDate],
[SysStartTime],
[SysEndTime]
FROM [dbo].[Account] FOR SYSTEM_TIME AS OF '2015-11-08T21:45:00';
GO
SELECT [AccountID],
[AccountName],
[AccountNumber],
[Address],
[Telephone],
[CreateDate],
[ModifiedDate],
[SysStartTime],
[SysEndTime]
FROM [dbo].[Account] FOR SYSTEM_TIME BETWEEN '2015-11-01' AND '20151231';
GO
Here are the two result sets. You can click on the image to view it full size:

The first result shows the data before the UPDATE ran. Notice how SysEndTime is the same value as the primary row’s SysStartTime and identical to the ModifiedDate value. This is why I stated previously that the ModifiedDate column is now redundant. We can convert this to a persisted computed column, based on SysStartTime.
In my next post, I will cover some of the things happening under the covers to make this magic work.