A friend of mine in the filmmaking business, who is exceedingly bright but has never worked with SQL Server before, was reading through the first five posts of this Database Fundamentals series, and asked a great question:
“I guess I’m not understanding what a byte is. I think I’m circling the drain in understanding it, but not floating down.”
She has a way with words.
I answered her immediately, but it reminded me that I did get a little carried away with data types, assuming that everyone reading that post would understand what a byte is.
In the innards of the computer is the CPU, or Central Processing Unit (there might be more than one in a server). The CPU is best described as a hot mess of on-off switches.

Just as it is in your house, a switch only has two states. This is what “binary” means. When the CPU clock ticks over, billions of times per second, if a switch is open, it’s a 0 (electricity cannot pass through it). If the switch is closed, it’s a 1 (electricity can flow to complete the circuit).
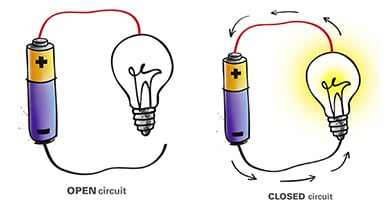
(Source: https://diytechpro.com/electric-circuit-simple-concept/)
The CPU (and memory, and storage system, and network) understand binary, and the software that sits on top of it uses binary as well.
We end up with a series of 1s and 0s that, when arranged in different combinations, represent information in some form or another. Each of these is a binary digit, or bit.
Through a series of decisions in the old days of computing, when we stick eight of these bits of data together, they form a byte.
Now comes the mathematical part of today’s post.
If we have 8 digits that can store two values each, we get a total of 2 x 2 x 2 x 2 x 2 x 2 x 2 x 2 combinations. This is more easily typed as 2^8, or 256. In other words, a byte can store a maximum of 256 values.
Here’s a short list of bytes to give you an example (I have not listed every one of the 256 possibilities). We write the bits in groups of four to make them easier to read.
| Binary | Decimal | ASCII | Binary | Decimal | ASCII |
| 0010 0000 | 32 | <space> | 1000 0001 | 129 | Å |
| 0010 0001 | 33 | ! | 1000 0010 | 130 | Ç |
| 0010 0010 | 34 | “ | 1000 0011 | 131 | É |
| 0010 0011 | 35 | # | 1000 0100 | 132 | Ñ |
| 0010 0100 | 36 | $ | 1000 0101 | 133 | Ö |
| 0010 0101 | 37 | % | 1000 0110 | 134 | Ü |
| 0010 0110 | 38 | & | 1000 0111 | 135 | á |
| 0010 0111 | 39 | ‘ | 1000 1000 | 136 | à |
| 0010 1000 | 40 | ( | 1000 1001 | 137 | â |
| 0010 1001 | 41 | ) | 1000 1010 | 138 | ä |
| 0010 1010 | 42 | * | 1000 1011 | 139 | ã |
| 0010 1011 | 43 | + | 1000 1100 | 140 | å |
| 0010 1100 | 44 | , | 1000 1101 | 141 | ç |
| 0010 1101 | 45 | – | 1000 1110 | 142 | é |
| 0010 1110 | 46 | . | 1000 1111 | 143 | è |
| 0010 1111 | 47 | / | 1001 0000 | 144 | ê |
| 0011 0000 | 48 | 0 | 1001 0001 | 145 | ë |
| 0011 0001 | 49 | 1 | 1001 0010 | 146 | í |
| 0011 0010 | 50 | 2 | 1001 0011 | 147 | ì |
| 0011 0011 | 51 | 3 | 1001 0100 | 148 | î |
| 0011 0100 | 52 | 4 | 1001 0101 | 149 | ï |
| 0011 0101 | 53 | 5 | 1001 0110 | 150 | ñ |
| 0011 0110 | 54 | 6 | 1001 0111 | 151 | ó |
| 0011 0111 | 55 | 7 | 1001 1000 | 152 | ò |
| 0011 1000 | 56 | 8 | 1001 1001 | 153 | ô |
| 0011 1001 | 57 | 9 | 1001 1010 | 154 | ö |
| 0011 1010 | 58 | : | 1001 1011 | 155 | õ |
| 0011 1011 | 59 | ; | 1001 1100 | 156 | ú |
| 0011 1100 | 60 | < | 1001 1101 | 157 | ù |
| 0011 1101 | 61 | = | 1001 1110 | 158 | û |
| 0011 1110 | 62 | > | 1001 1111 | 159 | ü |
| 0011 1111 | 63 | ? | 1010 0000 | 160 | † |
| 0100 0000 | 64 | @ | 1010 0001 | 161 | ° |
| 0100 0001 | 65 | A | 1010 0010 | 162 | ¢ |
| 0100 0010 | 66 | B | 1010 0011 | 163 | £ |
| 0100 0011 | 67 | C | 1010 0100 | 164 | § |
| 0100 0100 | 68 | D | 1010 0101 | 165 | • |
| 0100 0101 | 69 | E | 1010 0110 | 166 | ¶ |
| 0100 0110 | 70 | F | 1010 0111 | 167 | ß |
| 0100 0111 | 71 | G | 1010 1000 | 168 | ® |
| 0100 1000 | 72 | H | 1010 1001 | 169 | © |
| 0100 1001 | 73 | I | 1010 1010 | 170 | ™ |
| 0100 1010 | 74 | J | 1010 1011 | 171 | ´ |
| 0100 1011 | 75 | K | 1010 1100 | 172 | ¨ |
| 0100 1100 | 76 | L | 1010 1101 | 173 | ≠ |
| 0100 1101 | 77 | M | 1010 1110 | 174 | Æ |
| 0100 1110 | 78 | N | 1010 1111 | 175 | Ø |
| 0100 1111 | 79 | O | 1011 0000 | 176 | ∞ |
| 0101 0000 | 80 | P | 1011 0001 | 177 | ± |
| 0101 0001 | 81 | Q | 1011 0010 | 178 | ≤ |
| 0101 0010 | 82 | R | 1011 0011 | 179 | ≥ |
| 0101 0011 | 83 | S | 1011 0100 | 180 | ¥ |
| 0101 0100 | 84 | T | 1011 0101 | 181 | µ |
| 0101 0101 | 85 | U | 1011 0110 | 182 | ∂ |
| 0101 0110 | 86 | V | 1011 0111 | 183 | ∑ |
| 0101 0111 | 87 | W | 1011 1000 | 184 | ∏ |
| 0101 1000 | 88 | X | 1011 1001 | 185 | π |
| 0101 1001 | 89 | Y | 1011 1010 | 186 | ∫ |
| 0101 1010 | 90 | Z | 1011 1011 | 187 | ª |
| 0101 1011 | 91 | [ | 1011 1100 | 188 | º |
| 0101 1100 | 92 | \ | 1011 1101 | 189 | Ω |
| 0101 1101 | 93 | ] | 1011 1110 | 190 | æ |
| 0101 1110 | 94 | ^ | 1011 1111 | 191 | ø |
| 0101 1111 | 95 | _ | 1100 0000 | 192 | ¿ |
| 0110 0000 | 96 | ` | 1100 0001 | 193 | ¡ |
| 0110 0001 | 97 | a | 1100 0010 | 194 | ¬ |
| 0110 0010 | 98 | b | 1100 0011 | 195 | √ |
| 0110 0011 | 99 | c | 1100 0100 | 196 | ƒ |
| 0110 0100 | 100 | d | 1100 0101 | 197 | ≈ |
| 0110 0101 | 101 | e | 1100 0110 | 198 | ∆ |
| 0110 0110 | 102 | f | 1100 0111 | 199 | « |
| 0110 0111 | 103 | g | 1100 1000 | 200 | » |
| 0110 1000 | 104 | h | 1100 1001 | 201 | … |
| 0110 1001 | 105 | i | 1100 1010 | 202 | |
| 0110 1010 | 106 | j | 1100 1011 | 203 | À |
| 0110 1011 | 107 | k | 1100 1100 | 204 | Ã |
| 0110 1100 | 108 | l | 1100 1101 | 205 | Õ |
| 0110 1101 | 109 | m | 1100 1110 | 206 | Π|
| 0110 1110 | 110 | n | 1100 1111 | 207 | œ |
| 0110 1111 | 111 | o | 1101 0000 | 208 | – |
| 0111 0000 | 112 | p | 1101 0001 | 209 | — |
| 0111 0001 | 113 | q | 1101 0010 | 210 | “ |
| 0111 0010 | 114 | r | 1101 0011 | 211 | ” |
| 0111 0011 | 115 | s | 1101 0100 | 212 | ‘ |
| 0111 0100 | 116 | t | 1101 0101 | 213 | ’ |
| 0111 0101 | 117 | u | 1101 0110 | 214 | ÷ |
| 0111 0110 | 118 | v | 1101 0111 | 215 | ◊ |
| 0111 0111 | 119 | w | 1101 1000 | 216 | ÿ |
| 0111 1000 | 120 | x | 1101 1001 | 217 | Ÿ |
| 0111 1001 | 121 | y | 1101 1010 | 218 | ⁄ |
| 0111 1010 | 122 | z | 1101 1011 | 219 | € |
| 0111 1011 | 123 | { | 1101 1100 | 220 | ‹ |
| 0111 1100 | 124 | | | 1101 1101 | 221 | › |
| 0111 1101 | 125 | } | 1101 1110 | 222 | fi |
| 0111 1110 | 126 | ~ | 1101 1111 | 223 | fl |
| 0111 1111 | 127 | 1110 0000 | 224 | ‡ | |
| 1000 0000 | 128 | Ä | 1110 0001 | 225 | · |
There are values missing from the above table, for characters that cannot be displayed correctly in a web browser. For a complete table showing all 256 characters, visit PC Guide.com.
How does this affect Unicode values? If you remember in our post about CHAR, NCHAR, VARCHAR and NVARCHAR data types, we discovered that the Unicode versions (those types starting with N) will use two bytes in memory and on disk to store a single character, compared to the non-Unicode (sometimes called ASCII or plain text) data types, which use only one byte per character.
The high-level reason for this is that some alphabets have more than 256 characters, so the code page (the full set of characters in upper- and lower-case where applicable, plus all the numbers, punctuation marks, and so forth) won’t fit in the 256 possibilities available in a single byte.
When we stick two bytes together however, we suddenly have as many as 2^16 values that we can store, for a total of 65,536 possibilities. This is mostly good enough if you’re not storing Japanese in SQL Server.
There are exceptions to this, where some kanji takes up four bytes per character. This is known as UTF-32 (Unicode Transformation Format, 32 bits per character). The good news is, SQL Server does support multi-byte characters wider than standard (UTF-16) Unicode, as long as we pick the correct collation.
I hope this answers any burning questions you may have had about bits and bytes.
Feel free to reach out to me on Twitter at @bornsql.
BONUS! Check out this great video on what a CPU looks like at a massive scale (link from Leon Adato):