If there’s one thing that SQL Server is really good at, it’s relationships. After all, a relational database management system without the relationships is nothing more than a place to store your stuff.
Last week we briefly looked at a denormalized table, and then I suggested that breaking it up into five separate tables would be a good idea. So good, in fact, that it took me more than 2,000 words to explain just the first table in our highly contrived example.
Assuming you have read through all those words, let’s attempt a much more condensed look at the other four tables. If you recall, we had:
- Transactions
- Products
- Customers
- Salespersons
- Stores
We tackled the Stores table first because everything is backwards when we design databases.
For the next three tables, I’m going to just show you how I would design them, without going into detail. Take a close look at Salespersons, though (which we’ll look at first) because it will give you a clue about how we link all the tables together finally in the Transaction table.
Then take a look at … PaymentTypes? ProductTypes? Colours? Categories? Sizes? Uh … What’s going on here? Where did all those tables come from? Luckily, T-SQL allows comments, which you’ll see below.
CREATE TABLE [Salespersons] (
[SalespersonID] SMALLINT NOT NULL IDENTITY(1,1),
[StoreID] SMALLINT NOT NULL,
[FirstName] NVARCHAR(255) NOT NULL,
[LastName] NVARCHAR(255) NOT NULL,
[EmailAddress] NVARCHAR(512) NOT NULL
CONSTRAINT [PK_Salespersons] PRIMARY KEY CLUSTERED ([SalespersonID] ASC)
);
-- List of possible payment types, (e.g. credit card, cheque)
CREATE TABLE [PaymentTypes] (
[PaymentTypeID] TINYINT NOT NULL IDENTITY(1,1),
[Description] VARCHAR(255) NOT NULL,
CONSTRAINT [PK_PaymentTypes] PRIMARY KEY CLUSTERED ([PaymentTypeID] ASC)
);
CREATE TABLE [Customers] (
[CustomerID] BIGINT NOT NULL IDENTITY(1,1),
[FirstName] NVARCHAR(255) NOT NULL,
[LastName] NVARCHAR(255) NOT NULL,
[EmailAddress] NVARCHAR(512) NOT NULL,
[Telephone] VARCHAR(25) NOT NULL,
[PaymentTypeID] TINYINT NOT NULL,
CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID] ASC)
);
-- List of possible product types (e.g. iPhone, iPhone cover, iPod)
CREATE TABLE [ProductTypes] (
[ProductTypeID] TINYINT NOT NULL IDENTITY(1,1),
[Description] VARCHAR(255) NOT NULL,
CONSTRAINT [PK_ProductTypes] PRIMARY KEY CLUSTERED ([ProductTypeID] ASC)
);
-- List of possible colours
CREATE TABLE [Colours] (
[ColourID] TINYINT NOT NULL IDENTITY(1,1),
[Description] VARCHAR(255) NOT NULL,
CONSTRAINT [PK_Colours] PRIMARY KEY CLUSTERED ([ColourID] ASC)
);
-- List of possible categories (5.5", 4.7", 4", 3.5")
-- This replaces "size", since we might use Size to denote storage
CREATE TABLE [Categories] (
[CategoryID] TINYINT NOT NULL IDENTITY(1,1),
[Description] VARCHAR(255) NOT NULL,
CONSTRAINT [PK_Categories] PRIMARY KEY CLUSTERED ([CategoryID] ASC)
);
-- List of possible sizes ("8GB", "16GB", "32GB", etc.)
-- Can also be used for other product types like laptops
CREATE TABLE [Sizes] (
[SizeID] TINYINT NOT NULL IDENTITY(1,1),
[Description] VARCHAR(255) NOT NULL,
CONSTRAINT [PK_Sizes] PRIMARY KEY CLUSTERED ([SizeID] ASC)
);
CREATE TABLE [Products] (
[ProductID] TINYINT NOT NULL IDENTITY(1,1),
[ProductTypeID] TINYINT NOT NULL,
[ColourID] TINYINT NOT NULL,
[CategoryID] TINYINT NOT NULL,
[SizeID] TINYINT NOT NULL,
[SellingPrice] SMALLMONEY NOT NULL,
CONSTRAINT [PK_Products] PRIMARY KEY CLUSTERED ([ProductID] ASC)
);
Those tables popped out of nowhere, didn’t they? Welcome to the world of normalization. To design a database properly, we come to the realisation that we can simplify the data input even more, reducing repeated values, and finding the most unique way of representing data. Products comprise product types. A single list of colours can be reused in various places. Payment types can be used for all sorts of transactional data.
We end up with a lot of tables when we normalize a database, and this is perfectly normal. When we want to read information out of the system the way senior management wants, we must join all these tables together.
The only way to join tables together in a safe and meaningful way is with foreign key relationships, where one table’s primary key is referenced in another table, with a matching data type.
The SalesPersons table has a StoreID column. As it stands, there’s no relationship between Stores and SalesPersons until we create the relationship using T-SQL.
ALTER TABLE [SalesPersons]
ADD CONSTRAINT FK_SalesPersons_Stores FOREIGN KEY (StoreID)
REFERENCES [Stores] (StoreID);
- Line 1: Inform SQL Server that we are altering an existing table
- Line 2: By adding a foreign key constraint (i.e. limiting what can go into the
StoreIDcolumn) - Line 3: By forcing it to use the values from the Stores table’s
StoreIDcolumn (i.e. the primary key).
In a relationship diagram, it looks like this (in SQL Server Management Studio’s Database Diagram tool):
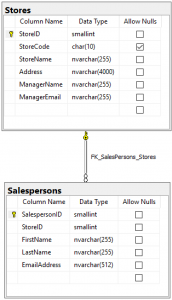
The yellow key in each table is the Primary Key (StoreID and SalespersonID respectively). There is a StoreID column in both tables with the same data type (SMALLINT). The foreign key (FK) does not have to match the name of the primary key (PK), but it makes things a lot easier to have the same name for both sides of a relationship in large databases, so it’s a good habit.
Notice the direction of the relationship (FK_Salespersons_Stores) in the picture, with the yellow key on the table with the Primary Key. The name of the relationship is also sensible. To the casual eye, this says that there’s a Foreign Key constraint in the Salespersons table that points to the Primary Key in the Stores table.
Now we see why data types are so important with relational data. A relationship is not even possible between two tables if the data type is not the same in both key columns.
With this constraint enabled, whenever we insert data into the Salespersons table, we have to make sure that whatever we put into the StoreID column must already exist in the Stores table.
Let’s do the rest of the relationships so far, and then we’ll look at the Transactions table.
ALTER TABLE [Customers]
ADD CONSTRAINT FK_Customers_PaymentTypes FOREIGN KEY (PaymentTypeID)
REFERENCES [PaymentTypes] (PaymentTypeID);
ALTER TABLE [Products]
ADD CONSTRAINT FK_Products_ProductTypes FOREIGN KEY (ProductTypeID)
REFERENCES [ProductTypes] (ProductTypeID);
ALTER TABLE [Products]
ADD CONSTRAINT FK_Products_Colours FOREIGN KEY (ColourID)
REFERENCES [Colours] (ColourID);
ALTER TABLE [Products]
ADD CONSTRAINT FK_Products_Categories FOREIGN KEY (CategoryID)
REFERENCES [Categories] (CategoryID);
ALTER TABLE [Products]
ADD CONSTRAINT FK_Products_Sizes FOREIGN KEY (SizeID)
REFERENCES [Sizes] (SizeID);
As we can see now, we have more than one foreign key relationship in the Products table, to ProductTypes, Colours, Categories, and Sizes, which is a clue to how the Transactions table will look.
CREATE TABLE [Transactions] (
[TransactionID] BIGINT NOT NULL IDENTITY(1,1),
[TransactionDate] DATETIME2(3) NOT NULL,
[ProductID] TINYINT NOT NULL,
[DiscountPercent] DECIMAL(4,2) NOT NULL DEFAULT(0),
[SalesPersonID] SMALLINT NOT NULL,
[CustomerID] BIGINT NOT NULL,
[HasAppleCare] BIT NOT NULL DEFAULT(0),
CONSTRAINT [PK_Transactions] PRIMARY KEY CLUSTERED ([TransactionID] ASC)
);
Let’s assume we’ve created all the relationships as well, so that we’re left with the following relationships (click to enlarge):
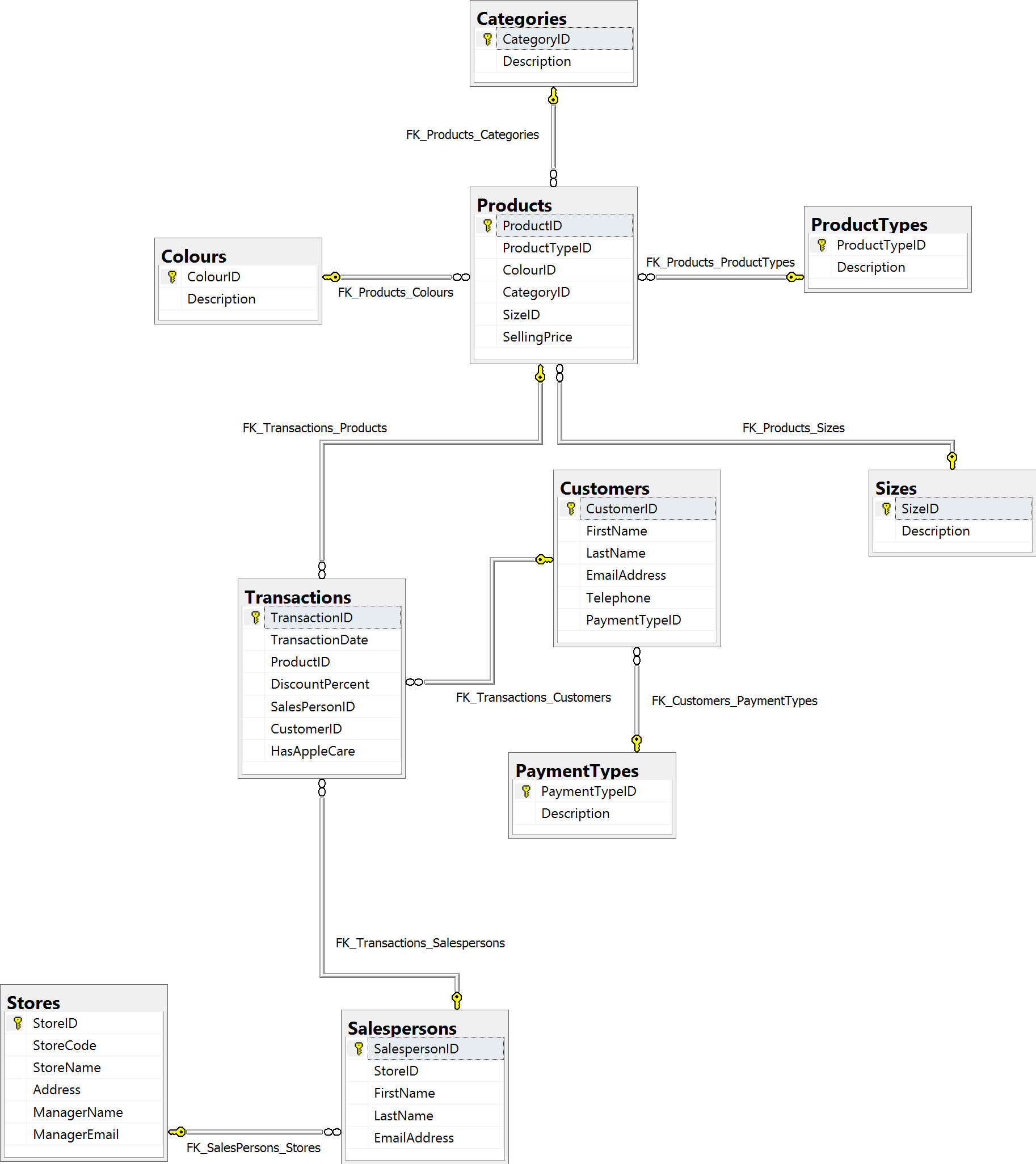
Ten tables, compared to our original one denormalized table, is a significant increase in number of tables. However, let’s compare the data usage for adding transactions.
If we were to populate each row of each table with enough data to provide the same number of transactions as last week’s two purchases, it would look like this.
Stores table: 172 bytes
- StoreID: 2 bytes (
IDENTITYvalue asSMALLINT) - StoreCode: 0 bytes (
NULL) - StoreName: 30 bytes (“Chinook Centre” is 14 characters long including the space, so with Unicode that becomes 28 bytes, plus 2 for the overhead of using
NVARCHAR) - Address: 86 bytes (“6455 Macleod Trail SW, Calgary, AB T2H 0K8” is 42 characters, so 84 with Unicode, plus 2 bytes for
NVARCHARoverhead) - ManagerName: 22 bytes (“Bob Bobson” in Unicode, plus 2 bytes
NVARCHARoverhead) - ManagerEmail: 32 bytes (“bob@example.com” in Unicode, plus 2 bytes
NVARCHARoverhead)
Salespersons table: 70 bytes
- SalespersonID: 2 bytes
- StoreID: 2 bytes
- FirstName: 14 bytes (“Thandi” in Unicode + 2 bytes)
- LastName: 14 bytes (“Funaki” in Unicode + 2 bytes)
- EmailAddress: 38 bytes (“thandi@example.com” in Unicode + 2 bytes)
PaymentTypes table: 14 bytes
- PaymentTypeID: 1 byte
- Description: 13 bytes (“Credit Card” + 2 bytes)
ProductTypes table: 23 bytes
- ProductTypeID: 1 byte
- Description: 8 bytes (“iPhone” + 2 bytes)
- ProductTypeID: 1 byte
- Description: 13 bytes (“iPhone Case” + 2 bytes)
Colours table: 21 bytes
- ColourID: 1 byte
- Description: 7 bytes (“Black” + 2 bytes)
- ColourID: 1 byte
- Description: 6 bytes (“Blue” + 2 bytes)
- ColourID: 1 byte
- Description: 5 bytes (“Red” + 2 bytes)
Categories table: 7 bytes
- CategoryID: 1 byte
- Description: 6 bytes (“5.5″” + 2 bytes)
Sizes table: 16 bytes
- SizeID: 1 byte
- Description: 7 bytes (“128GB” + 2 bytes)
- SizeID: 1 byte
- Description: 7 bytes (“256GB” + 2 bytes)
Products table: 27 bytes (3 products at 9 bytes each)
- ProductID: 1 byte
- ProductTypeID: 1 byte
- ColourID: 1 byte
- CategoryID: 1 byte
- SizeID: 1 byte
- SellingPrice: 4 bytes
Customers table: 192 bytes
- CustomerID: 8 bytes
- FirstName: 10 bytes (“I.M.” in Unicode + 2 bytes)
- LastName: 18 bytes (“Customer” in Unicode + 2 bytes)
- EmailAddress: 42 bytes (“customer@example.com” in Unicode + 2 bytes)
- Telephone: 16 bytes (“(403) 555-1212” + 2 bytes)
- PaymentTypeID: 1 byte
- CustomerID: 8 bytes
- FirstName: 10 bytes (“U.R.” in Unicode + 2 bytes)
- LastName: 18 bytes (“Customer” in Unicode + 2 bytes)
- EmailAddress: 44 bytes (“customer2@example.com” in Unicode + 2 bytes)
- Telephone: 16 bytes (“(403) 665-0011” + 2 bytes)
- PaymentTypeID: 1 byte
Transactions table: 96 bytes (32 bytes per transaction)
- TransactionID: 8 bytes
- TransactionDate: 7 bytes
- ProductID: 1 byte
- DiscountPercent: 5 bytes
- SalesPersonID: 2 bytes
- CustomerID: 8 bytes
- HasAppleCare: 1 bit (expands to 1 byte)
GRAND TOTAL: 638 bytes to represent all three transactions
The denormalized version, for which we can see the original example below, works out as follows. Recall we said last week that each column was NVARCHAR(4000), or possibly even NVARCHAR(MAX).

At our most generous, we would need 1,166 bytes to record these three transactions. That’s almost double the data required, just for these three. Plus, the data has no foreign key relationships, so we cannot be sure that whatever is being added to the denormalized table is valid.
As time goes on, the normalized tables will grow at a much lower rate proportionally. Consider what a denormalized Transactions table would look like with an average row size of 388 bytes, for ten million rows (3.6GB).
Compare that to a normalized database, with ten million transactions for 8 million customers. Even assuming we have a hundred products, with twenty colours, and 30 product types, we would see only around 1GB of space required to store the same data.
We know Apple as being one of the most successful technology companies in terms of sales, so extrapolating to 1 billion transactions, we’d be comparing 361GB (for the denormalized table) with less than half that (178GB) if every single customer was unique and only ever bought one item.
Aside from the staggering savings in storage requirements, normalization gives us sanity checks with data validation by using foreign key constraints. Along with proper data type choices, we have an easy way to design a database properly from the start.
Sure, it takes longer to start, but the benefits outweigh the costs almost immediately. Less storage, less memory to read the data, less space for backups, less time to run maintenance tasks, and so on.
Normalization matters.
Next week, we talk briefly about bits and bytes, and then we will start writing queries. Stay tuned.
Find me on Twitter to discuss your favourite normalization story at @bornsql.